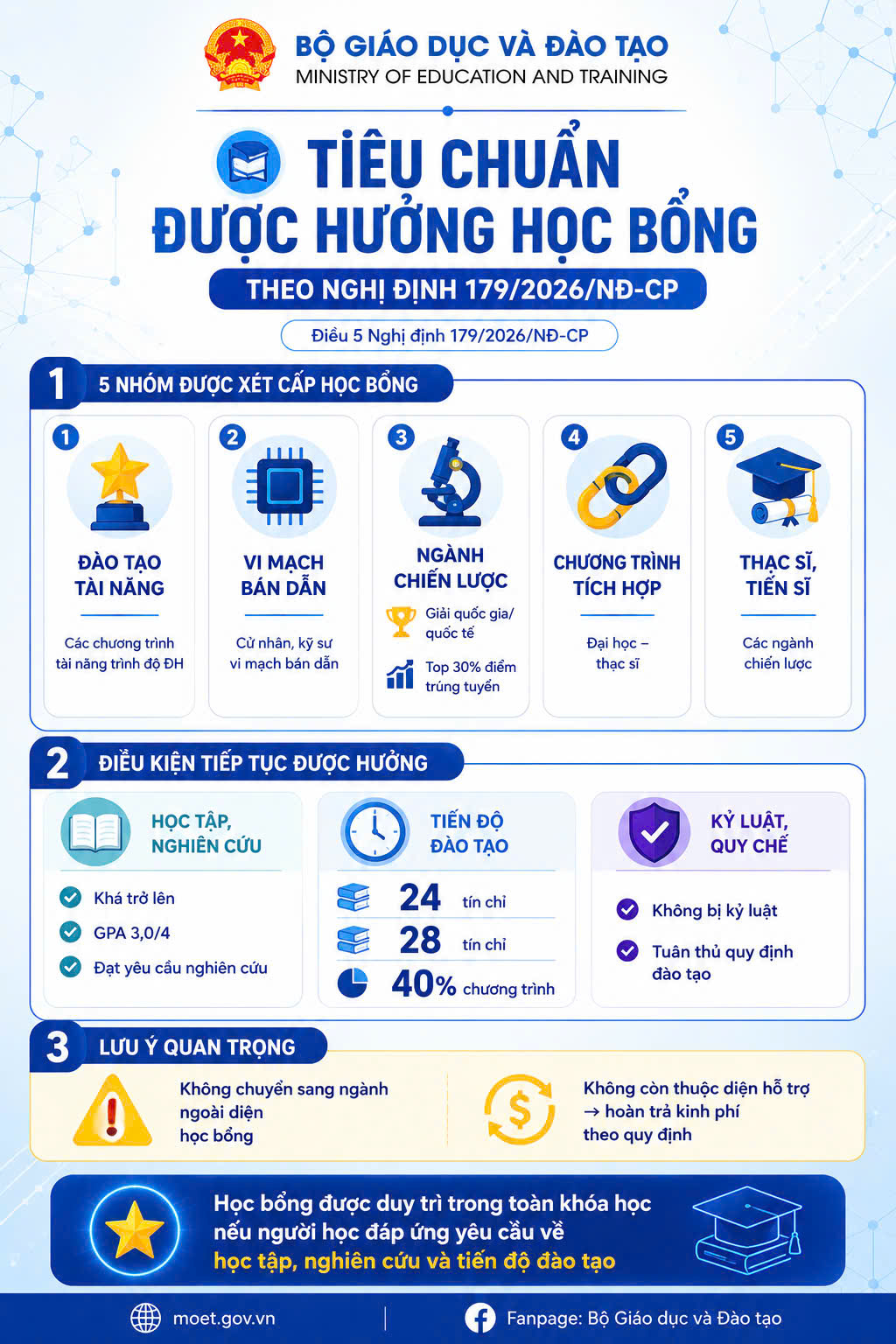
This article is my personal perspective based on professional experience and contrasted with public reports. The judgment may be subjective, but the information is based on reliable facts from a variety of sources..
In the current global digital infrastructure picture, the three pillars of cloud computing that in my view Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) almost hold the operating platform of the modern Internet world. From streaming services to e-commerce to digital banking to artificial intelligence, most of them are on these three-legged racks.
Illustration: foxbusiness
What just happened at the USEAST hotspot?
At dawn on October 20, 2025, U.S. time, around 11:00 – 16:10, Vietnam time, a series of global Internet services unexpectedly froze due to a serious incident originating from Amazon Web Services (AWS)’s US – EAST – 1 area (North Virginia).
It is AWS’s most critical infrastructure region, where a huge volume of platform services is concentrated. A minor glitch was enough to bring with it a series of AWS core services such as EC2 (virtual server) and DynamoDB (NoSQL database) to paralysis, leading to a domino effect across the ecosystem.
As a result, millions of users are unable to access popular apps: Snapchat, Fortnite, Duolingo, Canva, Wordle, Slack, monday.com, Zoom, as well as many banks and public services such as Lloyds, Barclays, Bank of Scotland, HMRC, Vodafone, among others.
According to the announcement on AWS’s service status page, the system is experiencing a DNS problem affecting DynamoDB – the database service that serves as a platform for many other applications in the aWS ecosystem.
The DNS (Domain Name System) is the system responsible for converting domain names into IP addresses, allowing browsers and applications to connect to the right servers to download and process data. When this DNS resolution layer malfunctions, applications are unable to locate the DynamoDB service resulting in a connection error, interrupting data retrieval, and thereby triggering a spreading effect to a host of other dependent services in the AWS infrastructure chain.
Surgical etiology
Here’s what I put together in a cause – and – effect model, prioritizing the possibilities with clear circumstantial evidence.
Note: AWS has not yet published detailed investigation reports beyond the carrier’s notification status, so these analyses are based on observed technical signs and past precedents. If there’s a definitive investigation, then all of the following are my speculations.
1. Error at Network or DNS control layer (Control Plane/Route 53)
Of course, the most likely hypothesis is an error in the process of resolving the domain name (DNS) to the endpoints of DynamoDB.
When DNS malfunctions, service dependencies can not find the correct “address” to access the data, causing many apps to fail.
In microservices architecture, a single error on Route 53 or a network control plane can quickly spread to components such as the Load Balancer (ELB) or Gateway API resulting in a spike in error rate of 5xx, unregistered users and blocked resource initialization tasks (EC2, ECS).
Estimated probability: 70 – 80%
2. Error during automatic configuration implementation
AWS operates the infrastructure as code (IaC) model, meaning that network, security, or coordination changes are automatically updated via pipelines.
If a bad configuration (e. g. VPC routing rules, IAM policies, or network settings) is widely deployed, it can cause “mixing” between the control and data layers causing the service to be disrupted en masse.
Estimated probability: 15 – 20%
3. Data cloning instability
While not the original cause, temporary inconsistencies between data copies can have serious consequences. When accessing unstable endpoints, the system generates a timeout, loses the login session, or interrupts the authentication stream which causes users to see the “frozen” application at boot time.
Estimated probability: 5 – 10%
4. Indirect influence from unusual traffic or infrastructure partners
Although AWS and cybersecurity agencies both deny the possibility of large – scale network attack, it is not possible to completely rule out the possibility that an unusual source of traffic (CDN, API, or third – party DNS provider) causes a load – crunching effect, triggering an existing error in the system.
This scenario is rarer, but can still contribute to an increase in crashes, especially when combined with an initial DNS error.
Estimated probability: <5%
Damage that can’t be measured in numbers.
As a cloud infrastructure provider to over 90% of Fortune 100 companies, AWS is seen as the backbone of global enterprise technology. So, the damage from this incident far outweighs the users’ temporary discomfort, it reveals the digital world’s enormous dependence on a single platform at a cost that could reach billions of dollars worldwide, though no one can pinpoint the exact number.
According to industry estimates, large-scale Internet disruptions cause billions of dollars in losses each year, including revenue loss, productivity decline, and long-term reputation damage. A 2024 survey cited in DataCentre Magazine found:
- Seventy-six percent of global businesses are running AWS applications.
- 48% of programmers integrate AWS into the software development process
In that context, the question is no longer “Can the AWS collapse?” but rather “How much havoc will it be when that happens?”.
From my cybersecurity lens, the October 20, 2025, AWS incident illustrates the concept of a Single Point of Failure (SPOF), an error point that can bring down a system.
In this case, the DNS malfunctioned at a critical infrastructure node, paralyzing a series of services despite the fact that the data was intact. Focusing infrastructure on ” super-regions ” such as US-EAST-1 amplified the risks, the dense interconnection of cloud computing made the sphere of influence much wider and deeper.
This incident is not unique. For years, major AWS disruptions have revolved around the US – EAST – 1 region, and as recently as 2024, the world was shocked by the incident. CrowdStrike Incident July 19, 2024. Both incidents showed that the global digital supply chain was dangerously dependent on a handful of core suppliers, dragging on spreading risk that many organizations had not yet anticipated.
My suggestion, and perhaps better understood by the younger generation of anatomists, is that as we become deeply dependent on the three pillars of the cloud — AWS, Microsoft, Google — the responsibility of the technologist, the operator and the leader should be to actively look toward risk – spreading, rather than waiting for the next incident to startle us.
If there’s more information about the incident, I’ll keep you updated in the next analysis!